概述
本文主要介绍以太坊中的 Merkle Patricia Tree。
Merkle Patricia Tree (MPT),顾名思义,同时具有基数树和哈希树的特点。一方面,MPT 能够像基数树一样进行键值对的存储和高效的索引,另一方面,其还具备哈希树的数据验证能力。
考虑上篇中提到的哈希树,可以认为是将哈希算法结合到二叉树中,即将二叉树中的子节点指针使用哈希指针代替。MPT 则可以认为是将哈希算法结合到基数树中,将基数树中的子节点指针使用哈希指针代替。
由此可知,所谓的 MPT 其实就是基数树,只不过改用哈希指针链接子节点。这样做的目的是方便存储到 K-V 数据库中,同时给予数据结构数据验证的能力。因此,下面先介绍一下基数树的构建。
基数树的构建
考虑上节提到的基数树如下:
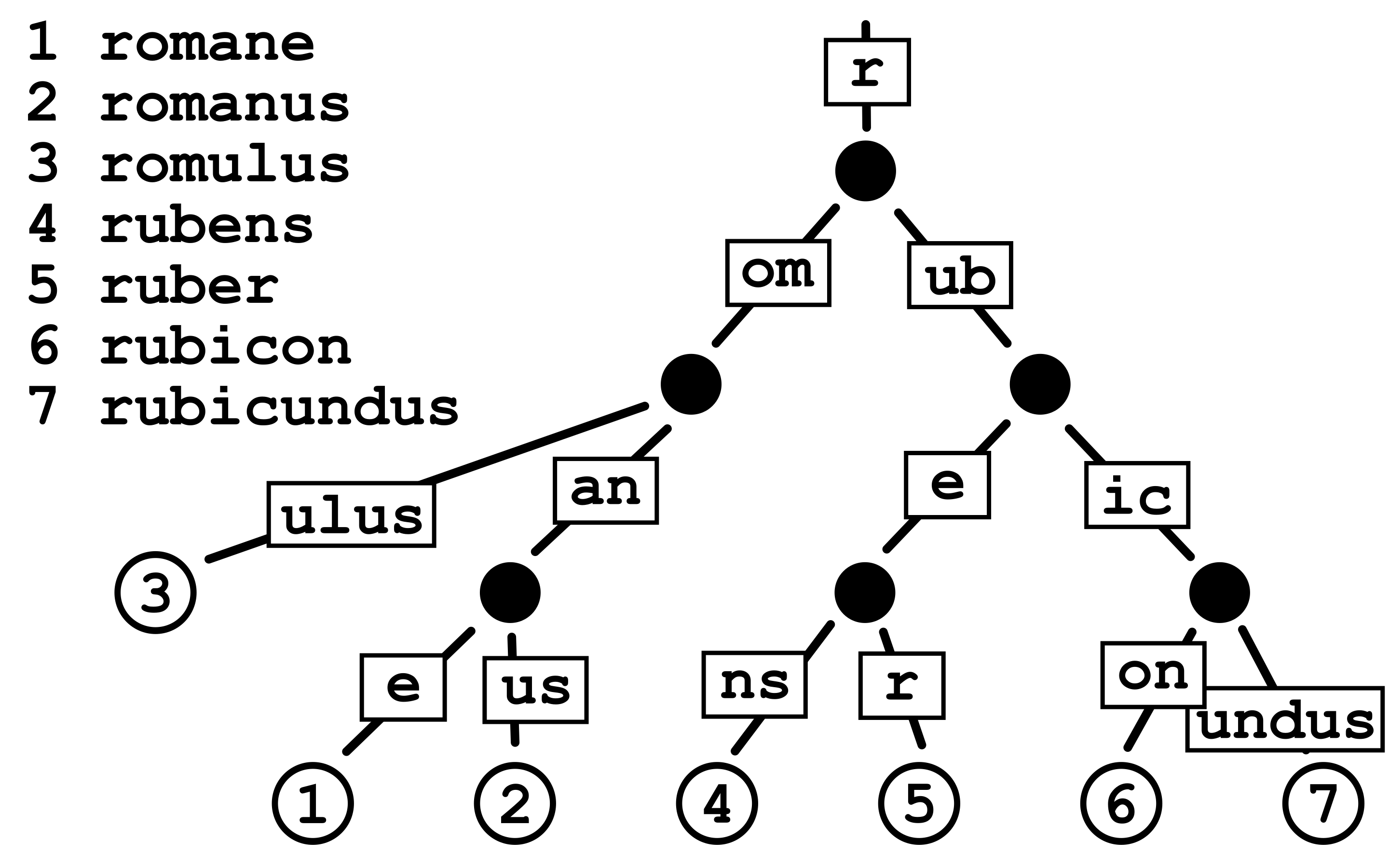
基数树的构建过程需要考虑每个分支的公共前缀。
- 初始分支需要考虑所有的键值对(图中单词是键,数字是值)的公共前缀,为
r,因此r为根节点。
1 | r omane |
- 接着考虑
r之后的字符情况。由于公共前缀有两种情况om和ub,因此产生分支。
1 | r: |
- 接着每个分支分别得到公共前缀:
1 | r: |
- 没有更多分支的叶子节点,填入从根节点到该叶子节点的路径上存储的键值对的值:
1 | r: |
- 补全剩余叶子节点的值:
1 | r: |
示意图如前所示。例如寻找 rubicon 对应的值,流程如下:
- 从根节点开始,为
r与rubicon前缀相同,ubicon进入下一层。 - 第二层与
ub匹配,icon进入ub分支。 - 第三层与
ic匹配,on进入ic分支。 - 第四层与
on匹配,键值匹配结束,取该节点对应值为6,得到rubicon -> 6,结束。
下面寻找 rom 对应的值,流程如下:
- 从根节点开始,
r匹配,om进入下一层。 - 第二层与
om匹配,键值匹配结束,该节点没有对应的值,因此键rom对应的值未找到,结束。
以太坊中的 Patricia Tree
以太坊中的基数树类似于上一节提到的基数树,不过有一些不同。首先,树使用的字母表为 {0, 1, 2, ..., f}。例如对于键值 do,其 ASCII 码对应的十六进制表示为:64 6f,因此对串 646f 进行前缀匹配(类似上一节的过程,只不过字母表从 {a, b, c, ..., z},变为 {0, 1, 2, ..., f})。
其次,为了方便进行存储,以太坊的对前缀树进行了改进,其树节点包含四种类型:
- NULL 节点
表示空串 - Branch 节点
节点包含 17 个元素表示为[v0, v1, v2, ..., vf, value],其中vn表示前缀中({0, 1, 2, ..., f})的一个字母对应的下层节点指针,value表示一个键值对的值。 - Leaf 节点
节点包含 2 个元素表示为[v0, value],其中v0表示一个字母组成的串,例如6e,6ef等。value表示一个键值对的值。 - Extension 节点
节点包含 2 个元素表示为[v0, key],其中v0表示一个字母组成的串。key表示指向下一层节点的指针。
下面举例说明以太坊中的 MPT 构建,假设需要存储下面键值对:
1 | ('do', 'verb'), |
将键值转为十六进制串(其中空格只是为了方便描述):
1 | ('64 6f', 'verb'), |
首先取所有键值对的公共前缀 6 为根节点,由于该节点不是叶子节点,也没有产生多个分支 (6 是所有键值对的前缀),所以根节点应该是一个 Extension 节点。这里用如下形式表示一个节点,之后相同:
1 | ${指向节点 X 的指针}: ${节点 X} |
得到当前构建的树如下:
1 | root: [6, key] |
其中 key 表示指向下一层节点的指针,待填写,下同。
接下来,所有键值对中有两种前缀 4 和 8,因此使用 Branch 节点。同时 v4 和 v8 有指向下一层的指针:
1 | root: [6, node1] |
其中 <> 表示没有值。root 节点中的 key 填为指向新增 Branch 节点的指针 node1。
对于前缀为 4 的分支,所有节点都有相同的公共前缀 6f,同时有一个节点已经完整添加到树中(64 6f),因此添加一个 Extension 节点(不是 Leaf 节点是因为还有未加入的键值以此节点为前缀);而 8 所在分支只有一个元素,直接添加一个叶子节点,其值为 stallion:
1 | root: [6, node1] |
然后,由于 node2 对应的 key 值指向的节点 1. 需要以 verb 为值(为 64 6f 对应的值);2. 不能为 Leaf 节点因为还有未添加的键。因此 key 指向的节点应为 Branch 节点,且其 value 为 verb。同时,此时 puppy 和 coin 有公共前缀字母 6,因此添加的 Branch 如下:
1 | root: [6, node1] |
接下来,未存的键值对前缀为:
1 | ('7', 'puppy'), |
有公共前缀 7,因此添加一个 Extension 节点(不能为 Leaf 节点因为还有未添加的键):
1 | root: [6, node1] |
key 对应的节点的 value 为 puppy,同时不能是 Leaf 节点,所以为 Branch 节点,同时,取 coin 对应键值前缀字母 6 形成分支:
1 | root: [6, node1] |
最后,coin 剩余前缀 5,且没有其他节点,因此插入一个叶子节点:
1 | root: [6, node1] |
为了对前缀进行对齐(例如 node7 的前缀 5 只有半个字节,补全为一个字节方便存储)和区分 Leaf 节点和 Extension 节点,对 Leaf 节点和 Extension 节点按下面规则添加前缀:
- 对于 Leaf 节点,如果前缀值长度不是一个字节的整数倍,添加半个字节的前缀
3, 例如node7补全为node7: [35, 'coin'] - 对于 Leaf 节点,如果前缀值长度是一个字节的整数倍,添加一个字节的前缀
20,node3补全为node3: [20 6f 72 73 65, 'stallion'] - 对于 Extension 节点,如果前缀值长度不是一个字节的整数倍,添加半个字节的前缀
1,例如root节点补全为root: [16, node1] - 对于 Extension 节点,如果前缀值长度是一个字节的整数倍,添加一个字节的前缀
00,例如node2补全为node2: [00 6f, node4]
对于上面例子进行补全得到:
1 | root: [16, node1] |
以太坊中的 Merkle Patricia Tree
以太坊的基数树中,每个节点使用一个特殊的指针指向,并在父节点中只用该值访问该节点。下面说明该值求法。
首先,由于每个节点都是一个字节数组(已经进行了补齐)node,以太坊首先对字节数组进行 RLP 编码 得到 RLP(node)。接下来定义一个函数 H(x): x >= 32 ? sha3(x) : x,最终指向 node 节点的指针为 H(RLP(node)),有时候也被称为哈希指针。例如上面的 pointer of node7 = hash7 = H(RLP(<0x35, 'c', 'o', 'i', 'n'>)) 。
将上面的例子的基数树使用哈希指针代替得到以太坊中的 MPT:
1 | rootHash: [16, hash1] |
此时只要保存 rootHash,当 MPT 中存储的键值对被篡改时便可以被检测到,因为此时 rootHash 也会发生变化。
在以太坊中,所有的数据最终通过键值对的形式存在了底层的数据库中,相对于直接存储数据:
1 | ('do', 'verb'), |
以太坊将数据整理成 MPT 再进行存储(此时存储的内容变为 (H(RLP(node)), node) 对)。此时,只要将该树的 rootHash 存储在区块中,就可以防止树中的数据被篡改。
1 | (rootHash, [16, hash1]) |
小结
MPT 是以太坊中的重要的数据结构,单个区块中的交易及其对应的交易、以太坊的世界状态、智能合约数据等,都使用了 MPT 的数据结构,并将这些 MPT 的根哈希值存储到了以太坊的区块中,用于数据防篡改和验证。
MPT 基于压缩的前缀树基数树构建,更加节省空间;同时,MPT 提供了方便的数据验证能力,使得只需要得到真实可信的 rootHash,就可以对树中的信息进行验证(同时,验证时不需要获取整棵树,只需要展开相关路径即可,使得验证过程更为简单),为数据提供防篡改的能力。
参考资料
Patricia Tree · ethereum/wiki Wiki
以太坊MPT原理,你最值得看的一篇